Context Management Strategies: The Enterprise AI Infrastructure Most Teams Are Missing

Ryan McCarroll
May 13, 2026
2 min read

What Are Context Management Strategies?
The Question Every Enterprise AI Team Is Getting Wrong
If you search "context management strategies," most results give you the same advice: compress your prompts, optimize your retrieval pipeline, use a sliding window for long conversations.
That advice solves the wrong problem.
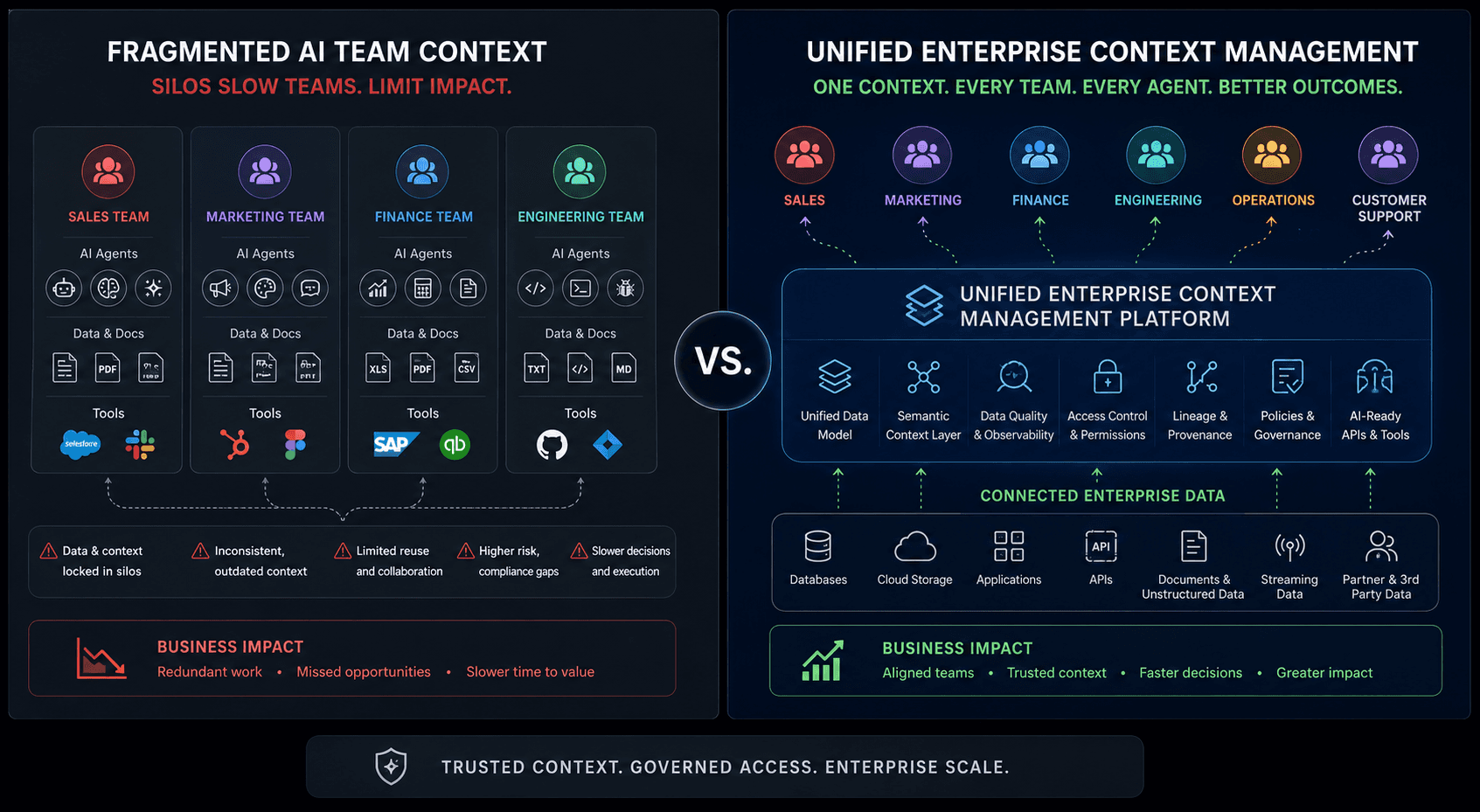
For a single AI application, yes, those tactics matter. But for an enterprise running dozens of AI initiatives across multiple teams, the real problem is not what happens inside a context window. The real problem is that every team is independently building its own retrieval infrastructure, choosing its own embedding models, and pulling from data sources that nobody has verified, governed, or documented.
That is not a strategy. That is fragmentation at scale.
According to the State of Context Management Report 2026, 88% of organizations believe they have a fully operational context platform, yet 61% frequently delay AI initiatives due to a lack of trusted data. That gap between perceived readiness and operational reality is where most AI projects stall and die.
This article explains what context management strategies actually are at the organizational level, why application-layer tactics alone cannot close that gap, and what five strategies separate enterprises that successfully scale AI from those stuck in perpetual proof-of-concept.
What Is a Context Management Strategy? (Clear Definition)
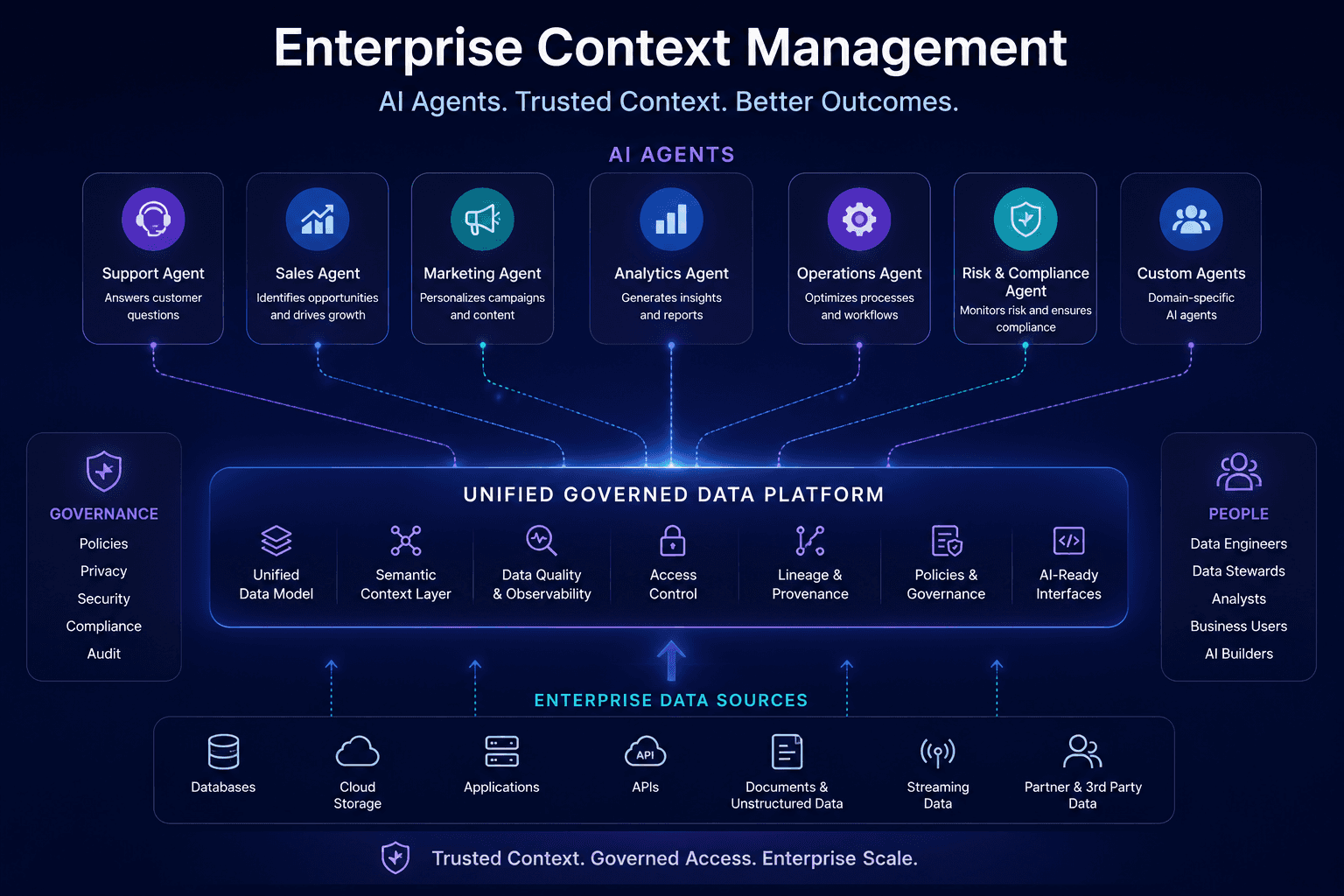
A context management strategy is an organizational approach to reliably delivering the most relevant, verified, and governed data to AI context windows across an entire enterprise.
This is not the same as context engineering. Here is the distinction that matters:
Context engineering handles what happens inside a single agent or application. It covers memory management, prompt optimization, retrieval-augmented generation (RAG), tool calling, and structured outputs. These are valuable capabilities.
Context management is the organizational layer above context engineering. It governs where context comes from, who is responsible for its quality, what compliance rules apply, and how consistency is maintained when 20 different teams are building 50 different agents from the same underlying data.
The analogy that captures this best: Early web applications each built their own login systems. It worked until enterprises had hundreds of applications and thousands of users, at which point the fragmentation became untenable and organizations adopted centralized identity management. Context management is the same inflection point, now arriving for AI infrastructure.
Context Engineering | Context Management | |
Scope | Individual application or agent | Entire organization and all data assets |
Source of truth | Bespoke vector databases per team | Unified, governed context graph |
Security model | Perimeter-based, manual approvals | Centralized retrieval with role-based access control |
Scalability | Limited by manual documentation | Governance-as-code and automated lineage |
The context management strategies that DataHub documents across enterprise deployments all share a common starting point: governance and lineage built into the infrastructure layer before a single agent reaches production, not added as an afterthought when compliance starts asking questions.
Why Application-Layer Tactics Are Not Enough
Context window management techniques like hierarchical memory systems, prompt compression, and selective context injection all solve real engineering problems. They make individual agents more capable, more cost-efficient, and better at maintaining coherence across long conversations.
But none of them answer the questions that actually block enterprise AI from reaching production:
Where did this context come from? Can you prove its lineage? Is this dataset approved for this use case? Who verified it, and when?
These are the questions legal, compliance, and security teams ask before any agent touches production data. They live outside the application layer entirely. No amount of prompt engineering answers them.
Gartner predicts that by 2027, 40% of agentic AI projects will be canceled, largely due to foundational infrastructure gaps that a proper context management strategy is designed to address.
The pattern mirrors what happened with microservices. Teams moved fast, built independently, and discovered a few years later they had an operational nightmare of duplicated logic, inconsistent APIs, and no single authoritative source. The same arc is playing out with AI context infrastructure, except faster, and with outputs that directly influence business decisions.
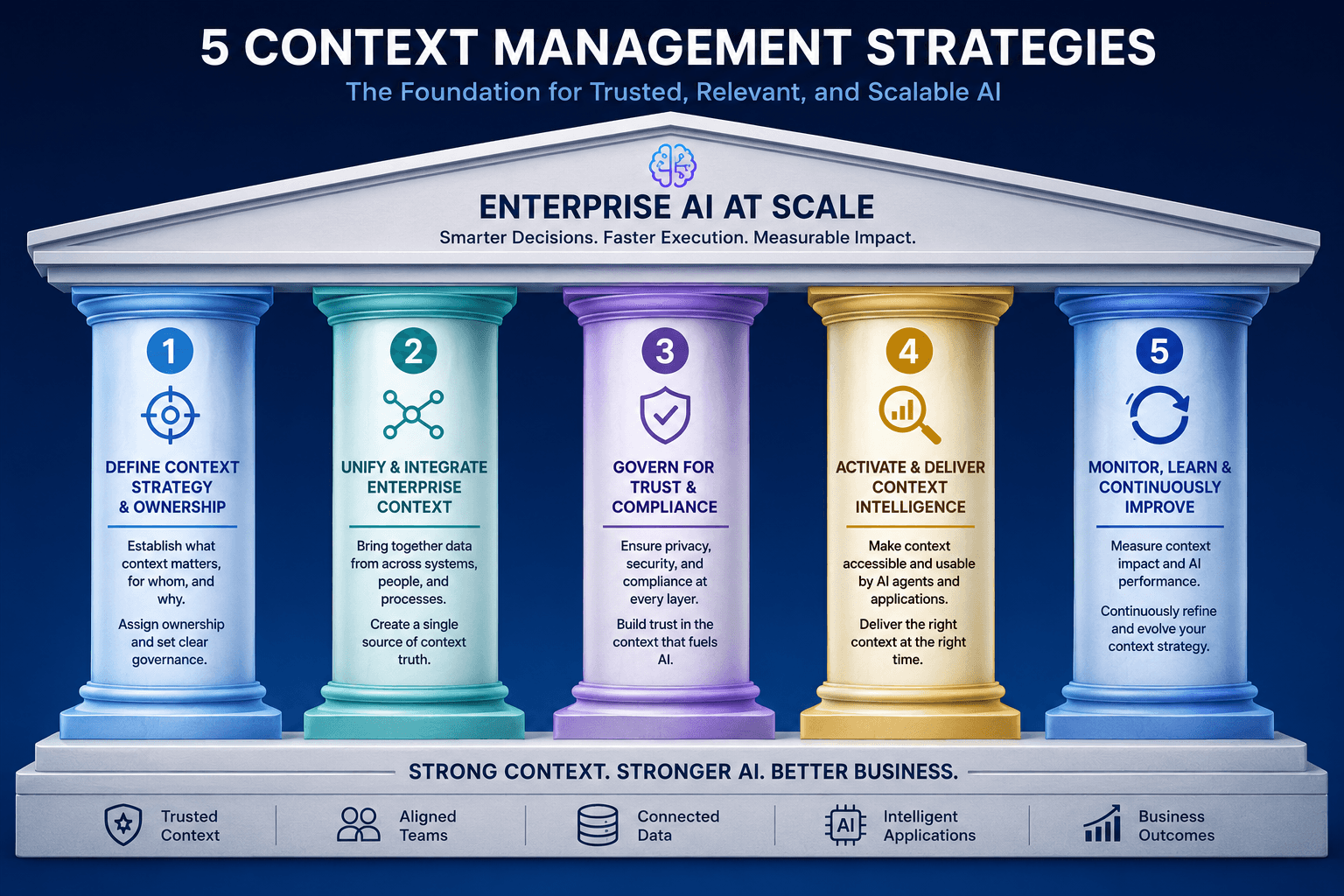
Five Context Management Strategies That Actually Scale
These are not application-layer tactics. They are organizational decisions that shape how context flows across an entire AI portfolio.
1. Treat Context as Shared Infrastructure
The most important shift an enterprise can make is treating context as shared infrastructure rather than a team-specific resource.
When every AI team builds its own context layer, you get duplicated effort, inconsistent data quality, and no organizational leverage. One team's "customer" definition differs from another team's. One pipeline pulls from an approved source; another does not. The outputs diverge, and nobody knows which agent to trust.
Shared context infrastructure means a single governed layer serving every agent, every application, and every team. Investment in metadata quality, business definitions, and documentation compounds across every AI initiative rather than being rebuilt from scratch each time.
The 2026 State of Context Management Report found that 93% of organizations say they are likely to treat context as shared infrastructure rather than team-specific tooling in the coming year, signaling that this shift is recognized as essential even where it has not yet been implemented.
2. Establish Governance Before You Scale
Governance is routinely treated as a constraint to manage after AI is deployed. In practice, the absence of governance is what prevents deployment in the first place.
Without it, agents pull from datasets that were deprecated months ago. Columns containing personally identifiable information go unclassified. Models reason over training data from sources legal never approved for the use case. Each of these is a production incident waiting to happen, and none can be fixed at the retrieval layer.
A mature context management strategy builds governance into the infrastructure layer: clear data lineage tracing any agent output back to its source, classification and access controls that apply automatically rather than through manual review, and freshness contracts so agents do not silently reason over stale data.
The 2026 report found that 66% of organizations report AI models generating biased or misleading insights due to insufficient context from their data infrastructure. Governance built into the platform, rather than bolted on afterward, is the structural fix.
3. Build for Provenance and Trust
Trust is the throughput bottleneck for enterprise AI.
When compliance asks "where did this data come from?" and no one can answer quickly, projects stall. When an agent produces a recommendation and the business cannot verify the underlying data, adoption stalls. These are not technical failures. They are trust failures, and they are solved at the infrastructure layer, not the application layer.
A mature context management strategy bakes provenance into every piece of context that reaches an agent: automated lineage extraction across the full data supply chain, from source system through transformation to the context window itself.
Netflix provides a concrete example of what this looks like at scale. As the company's data ecosystem expanded into ads, live events, and games, its engineering team built a unified global catalog connecting data, machine learning, and software entities across the organization. The result was not just better discovery. It enabled cross-domain impact analysis and self-serve governance, giving teams a verified, unified view of technical assets across the enterprise.
Nitin Sarma, Senior Engineering Manager for Data Discovery and Governance at Netflix, described the underlying need clearly: organizations can no longer rely on legacy, siloed ways of organizing data. A more cohesive, centralized approach to how context is stored, where it lives, and how it is reasoned about holistically is no longer optional.
4. Close the Aspiration-Reality Gap
One of the most striking findings from the 2026 State of Context Management Report is the disconnect between self-assessed AI readiness and operational reality. 90% of organizations say they are "AI-ready," yet 87% cite data readiness as their biggest impediment to putting AI into production.
A strategy built on an honest audit of this gap will outperform one that assumes the foundation is already solid.
What does that audit look like? It means assessing what context your organization actually has versus what you believe you have. It means identifying which data sources are genuinely trusted versus which are treated as authoritative by convention. It means measuring governance coverage across your full data estate.
The 2026 priorities that data teams identified reflect this reality check. The top concerns are not advanced capabilities. They are foundational: AI-ready metadata (62%), context quality (55%), and trust and governance (48%).
5. Make Context Infrastructure Agent-Ready from Day One
As agentic AI moves from experimentation into production, every agent your organization deploys will need to discover, access, and reason over enterprise context. Designing your context infrastructure for consistent, standardized access from the start avoids a costly retrofit later.
Agent-ready context infrastructure means exposing your governed context graph through standardized protocols such as MCP servers, semantic search APIs, and native connectors for platforms teams already use. It means an agent can find the right data, verify its provenance, and respect governance policies without requiring custom integration work for every new application.
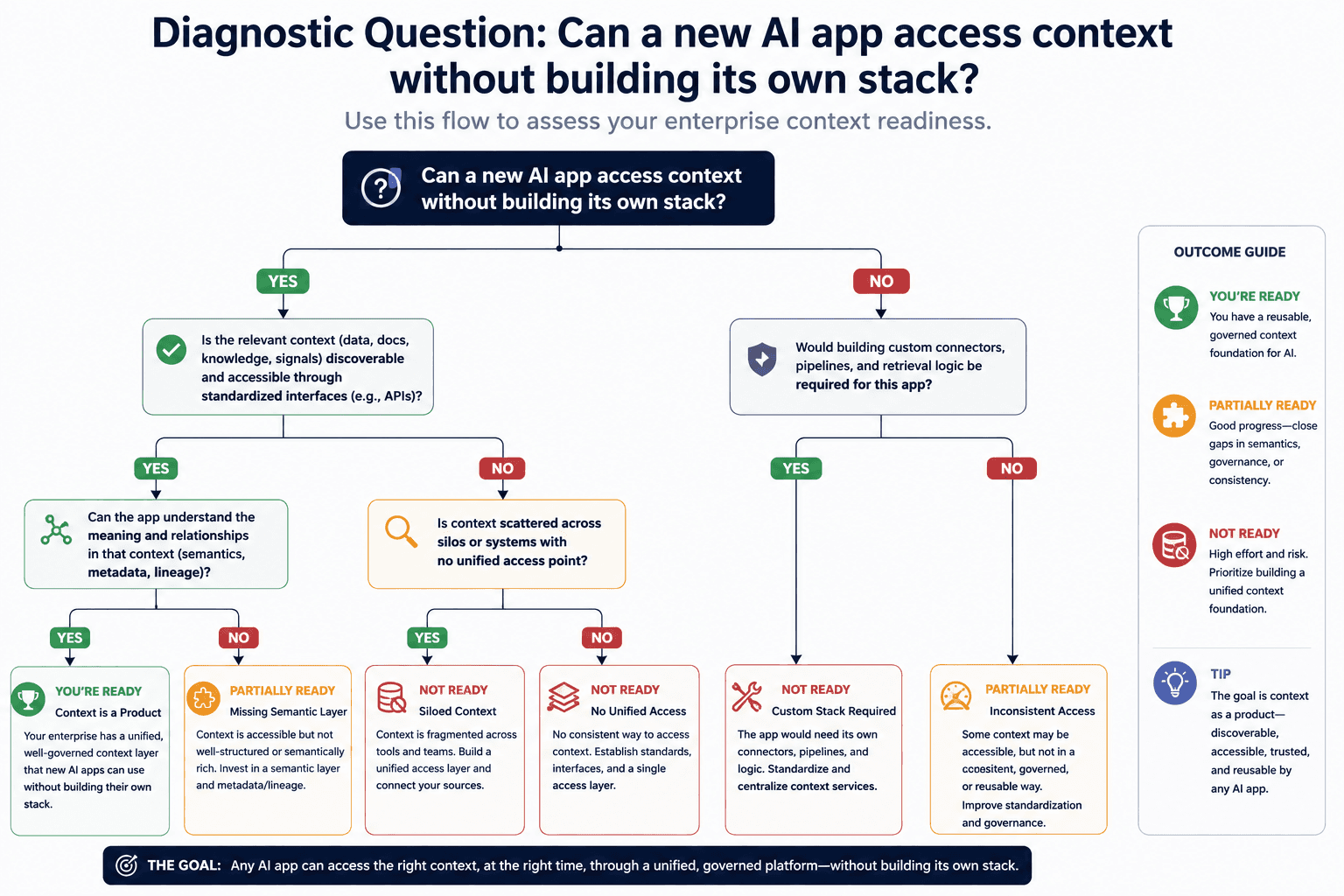
How to Tell If You Have a Strategy or Just Tactics
A useful diagnostic: if someone asked your organization "what is your context management strategy?" and the answer is a list of tools and techniques used by individual teams, you have tactics. If the answer describes how context flows, who governs it, and how consistency is maintained across applications, you have a strategy.
Four questions reveal which side of that line your organization sits on:
1. Can a new AI application access governed, trusted context without building its own retrieval infrastructure from scratch?
2. When a dataset changes upstream, do all downstream agents automatically reflect that change?
3. Can compliance trace any agent output back through the full chain of source data in under one business day?
4. If a domain owner updates a business definition, does that update propagate to every agent that references it?
The difference shows up in measurable, operational ways. Organizations with a strategy answer "where did this data come from?" in seconds, not weeks. They deploy new agents without rebuilding the context layer. They give compliance a full audit trail on demand.
Organizations with only tactics are rebuilding the same capabilities in every application, answering the same trust questions manually every time, and watching AI initiatives stall at the proof-of-concept-to-production boundary.
83% of IT and data leaders agree that agentic AI cannot reach production value without a context platform. The organizations that build this infrastructure proactively are the ones whose AI initiatives actually ship.
What a Context Platform Looks Like in Practice
A context platform is a unified infrastructure layer serving as the single source of truth for enterprise context. It connects technical metadata (schemas, lineage, quality metrics), operational context (access patterns, service-level agreements, system dependencies), and business knowledge (glossaries, documentation, domain expertise) into a single governed platform.
Rather than maintaining separate knowledge bases for human users and AI agents, a context platform delivers relevant context to both from one source of truth.
The critical capabilities a context platform must provide:
Automated lineage tracking so any agent output can be traced back to its originating data source without manual investigation.
Role-based access control applied at the infrastructure layer, not managed per-application by individual development teams.
Freshness contracts and SLA assertions so agents are not silently reasoning over outdated data.
Standardized agent access through protocols like MCP servers so new agents can be connected to governed context without custom integration work each time.
Frequently Asked Questions About Context Management Strategies
What is the difference between context management and RAG?
RAG (retrieval-augmented generation) is one mechanism for delivering context to AI models and it remains a powerful pattern. But RAG's reliability depends on the quality and governance of the underlying data. Without a context management strategy, each team builds its own RAG pipeline with its own vector database, embedding model, and retrieval logic. Context management provides the governed foundation that ensures every RAG implementation pulls from trusted, consistent sources.
Why do 40% of agentic AI projects get canceled?
According to Gartner, the primary reason is foundational infrastructure gaps, not model capability limitations. Agents that cannot access trusted, governed context at runtime cannot produce outputs that compliance, legal, and business stakeholders will accept for production use. Context management strategy directly addresses these infrastructure gaps.
How do you measure context management maturity?
Maturity can be assessed across several dimensions: whether context is treated as shared infrastructure or rebuilt per application, whether governance and lineage are automated or manual, whether agents access context through standardized protocols, and whether any AI output can be traced back to its source data. The 2026 State of Context Management Report found significant gaps between self-assessed maturity and operational capability, suggesting most organizations overestimate their readiness.
What is the first step to building a context management strategy?
Start with an honest audit of what context your organization actually has versus what it believes it has. Identify which data sources are genuinely trusted with documented lineage versus those treated as authoritative by convention. Then prioritize governance coverage before scaling the number of agents or AI applications.
Does context management strategy replace context engineering?
No. Context engineering remains essential for building capable individual agents. Context management is the organizational layer that makes context engineering reliable and consistent across an entire enterprise. Both are required. The error most organizations make is treating context engineering as sufficient on its own.
Summary: The Strategic Shift Enterprise AI Requires
The organizations scaling AI successfully in 2026 are not the ones with the best prompt engineers or the most sophisticated RAG pipelines. They are the ones that recognized context as a shared organizational asset and built the governance infrastructure to match.
Application-layer tactics will always be necessary. They are never sufficient at enterprise scale.
Treating context as shared infrastructure, establishing governance before scaling, building for provenance, closing the gap between AI readiness perception and reality, and making context infrastructure agent-ready from day one: these are the decisions that determine whether AI initiatives reach production or stay trapped in proof-of-concept indefinitely.



